In this article we’ll cover the basics of Aerospike’s Kubernetes operator and how we went about several engineering challenges we faced. We’ll then discuss the capabilities of the Aerospike Kubernetes Operator, and go over 3 engineering challenges we faced when developing it.
What Are Kubernetes Operators?
Kubernetes was designed to support automation of deployment and ongoing management of containerized applications in a cluster. Below are some key concepts and terms you’ll need to understand before we get into the specifics of the operator for Aerospike DB.
A Resource is an endpoint in the Kubernetes API that stores a collection of API objects of a certain kind. Several examples for resources include the built-in Pods, the Deployment or StatefulSet that create them, a Service that’s used to expose an application running on pods, and ConfigMap that’s used to store non-confidential data in key value pairs.
Controllers are control loops that watch the state of your cluster, then make or request changes where needed.
Custom Resource introduces your API into a cluster. This is an extension of the Kubernetes API that is not available in a default Kubernetes installation. It represents a customization of a particular Kubernetes installation and is fairly common.
A custom resource definition (CRD) file defines your own object kinds and lets the API Server handle the entire lifecycle.
Operators are clients of the k8s API, and they act as controllers for a custom resource.
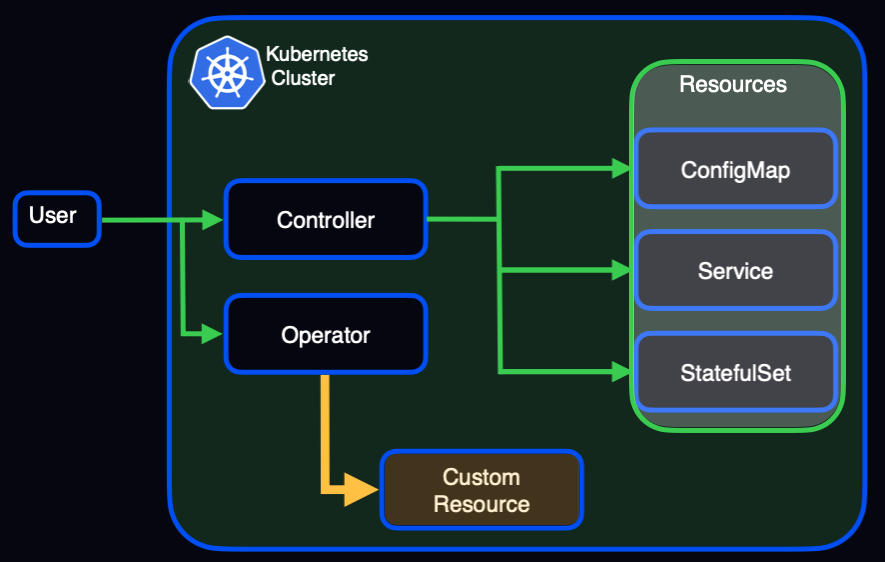
A visual explanation. Green: Kubernetes resources; Yellow: custom resources.
To summarize: Resources and Custom Resources define the particulars related to a specific application, in this case Aerospike Database. Controllers and operators control the resources and custom resources, respectively, providing a framework for deploying and managing complex distributed applications.
New complex distributed architectures have been developed to meet the demands of Internet scale. Simultaneously more agile development models have been adopted in order to meet the competitive demands to evolve applications on an ongoing basis. By providing a foundation for automation, Operators minimize the costs of personnel, and more importantly take the variability of human performance of repetitive tasks out of the equation.
Aerospike’s Features
Aerospike is a Real Time Data Platform that acts across billions of transactions while reducing the server footprint. The nature of it, and the requirements of our customers introduce some special considerations for what it can do, and how.
The Aerospike Kubernetes operator deploys the database clusters and handles everything related to cycle management. To name a few:
Cluster scale up and down (number of nodes per cluster as well as resource allocation per node)
Server version up- and downgrade
Converting YAML-based configurations to Aerospike configuration
Rack awareness management
Cluster access control management
Multi-cluster XDR setup (watch here to get a reminder of it spanning across different types of servers, in different geographical zones, and hardware or cloud or multi-cloud)
Security: TLS, user management, etc.
Monitoring of all of the above
There are many moving parts and the more we automate, the less room for human errors.
Three Engineering Challenges
Due to the special nature of the Aerospike database and the way it’s being used, we have encountered multiple interesting engineering challenges. Here are 3 of them.
1. Persistent Data
Each pod has a dedicated storage. This storage must be persistent because we do want the data to remain even if a pod is restarted.
So the behavioural logic is:
In case this is the first time you’re assigned a volume — clear it. Just like with computer memory, you cannot assume that the storage is going to be empty.
In case it’s a volume of a restarting pod — keep the data. It can happen that a pod restarts when changing the configuration, or just a hardware failure. This time, the data that exists in the volume is needed because it’s valid stored values.
But the problem is that there is no “Kubernetes way” of telling if the pod is a new one or a restarted one. In the scenario where the pod restarts due to configuration change, it’s likely that the image changed as well, and all the metrics were reset to zero.
The solution we came up with is using a restart flag in the init containers. These are the containers that are run before your containers run. In the init containers we wipe the data, and then add a flag in the configurations.
This way, when there’s a pod restart — the flag is already there to signal that the data should not be wiped.
2. Aborting a Rolling Update
Say that you have a rolling update and you’re updating a server version across 10 nodes.
In the middle you realize you need to abort and roll back. What happens?
The screen shows:
Node 1……Updated with v5.6 Node 2……Updated with v5.6 Node 3……Updated with v5.6
And this is where you hit abort.
What you want to see next is
Node 1……Updated with v5.5 Node 2……Updated with v5.5 Node 3……Updated with v5.5
Instead of
Node 4……Updated with v5.6 Node 5……Updated with v5.6 … Node 10…..Updated with v5.6 Node 1……Updated with v5.5 Node 2……Updated with v5.5 Node 3……Updated with v5.5
But that means you need to interrupt the command in the middle of its execution.
For this reason we implemented the setup in a way that after every operation the reconciliation requests are requeued. Basically, the operator is asking the API “Now what?”
This way, after completing updating node number 3 to the new version, the next step would be to ask “What do I do now?”. At this point the API will instruct to apply the old version to nodes 1–3!
To make things even more efficient the operator requests delay in the response. For example, let’s say the node is in the middle of a migration which takes 2 seconds. In this scenario, the operator will ask the API “Now what? Please respond in 2 seconds.”
The API will hold on with the replying, and this makes sure the operator will get the most up to date command, because a lot can happen in these 2 seconds.
Sounds like the straightforward and obvious thing to do? Definitely, but de facto not all operators are implemented this way.
3. Achieving Hyper—Scale
Cloud is great for starting fast and for easy maintenance, and indeed many companies are migrating their services to the cloud these days.
What happens when your customers go to really really large scale?
Many of our clients are already in the field of petabytes (that’s billiards, the one that comes after billions), and some are making their ways into the exabytes territory (that’s trillions). They all of course expect to keep the same SLAs of sub milliseconds.
We all know that the cloud is not homogeneous. The hardware you get is promised with a minimum CPU, but it doesn’t mean that all the CPUs have the exact same properties.
At a very large scale, these small differences start to show.
Aerospike’s architecture is disk heavy. Sharing resources means that you definitely get a slice but it’s hard to cap the size of it. This can mean that one machine might respond slowly to messages. In a distributed database, meta messages are moving around, in addition to the ones that carry data, for example for synchronization purposes. Delay that is caused because of different performance specs can escalate problems, at a very large scale.
Another potential problem is networking: when the network is not private, you get a slice of it, but you have to share. If you have noisy neighbors they can drive your performance down, and this can have a cascading effect.
Any of these interruptions are hard to predict, and an operator alone will not solve this.
The solution that some of our customers, who reached such scales, are doing is private cloud. In such a setup you own the whole host and split the resources internally. In this setup, some good practices include budgeting for some over capacity and maximizing the communication to a local one, to minimize latency influence.
In this setup too, the Kubernetes Operator is great. After all, Kubernetes started inside Google’s private cloud.
Let’s Recap
We covered the Kubernetes basic terminology around resources and controlling them.
We then discussed our considerations, as a distributed database that operates at a high scale in high speed, in building our own operator. Lastly, we covered 3 of the engineering challenges we had, and how we solved them.
The operator’s code is open source on GitHub, you’re welcome to read, learn and contribute!