When used with the Spark, Aerospike offers massively parallel storage to enable you to build high throughput and low latency ETL pipelines. Aerospike is a highly scalable NoSQL database and its hybrid memory architecture makes it an ideal database for Spark applications. It is typically deployed into real-time environments managing terabyte to petabyte data volumes and supports millisecond read and write latencies. It leverages bleeding-edge storage innovations such as PMem or persistent memory from best of breed hardware companies such as HPE and Intel. By storing indexes in DRAM, and data on persistent storage (SSD) and read directly from SSD, Aerospike provides unparalleled speed and cost-efficiency.
Aerospike Connect for Spark loads data from Aerospike into a Spark streaming or batch DataFrame in a massively parallel manner, so that you can process the data by using Spark APIs, which are supported in multiple languages, such as Java, Scala, and Python. A Spark connector can be easily added as a JAR to a Spark application, which can then be deployed in a Kubernetes or non-Kubernetes environment, either in the cloud or on bare-metal. It also enables you to efficiently write the DataFrame, batch or streaming, to Aerospike via the corresponding Spark write API. The Spark connector allows your applications to parallelize work on a massive scale by leveraging up to 32,768 Spark partitions (configured by setting aerospike.partition.factor) to read data from an Aerospike namespace storing up to roughly 550 billion records per namespace per node across 4096 partitions. For example, if you had a 256-node Aerospike cluster, which is the maximum allowed, you would be able to store a whopping 140 trillion records.
As shown in Figure 1, Spark allows its users to push down predicates in a query to the underlying database at scale, which essentially optimizes the query by limiting the data movement between the Spark cluster and the database. A predicate is a condition on a query that returns true or false, typically located in the WHERE clause. Spark treats a database such as Aerospike a DataSource Spark exposes that capability via the DataSource v2 API for filter pushdown. Figure 1 depicts how a simple Spark query in the SQL format is pushed down to the Aerospike database. Behind the scenes the Aerospike connector for Spark uses Aerospike expressions to accomplish it. If you are not familiar with Aerospike Expressions, you can read our documentation for details. Aerospike Expressions is basically a strongly typed, functional, domain-specific language designed for manipulating and comparing bins and record metadata in the database. You can use it to create powerful and efficient filters using a rich set of operators that are executed in the server. Based on how the filters are structured, you can significantly limit the data that moves between the Aerospike and Spark cluster, which will consequently speed up your Spark queries.
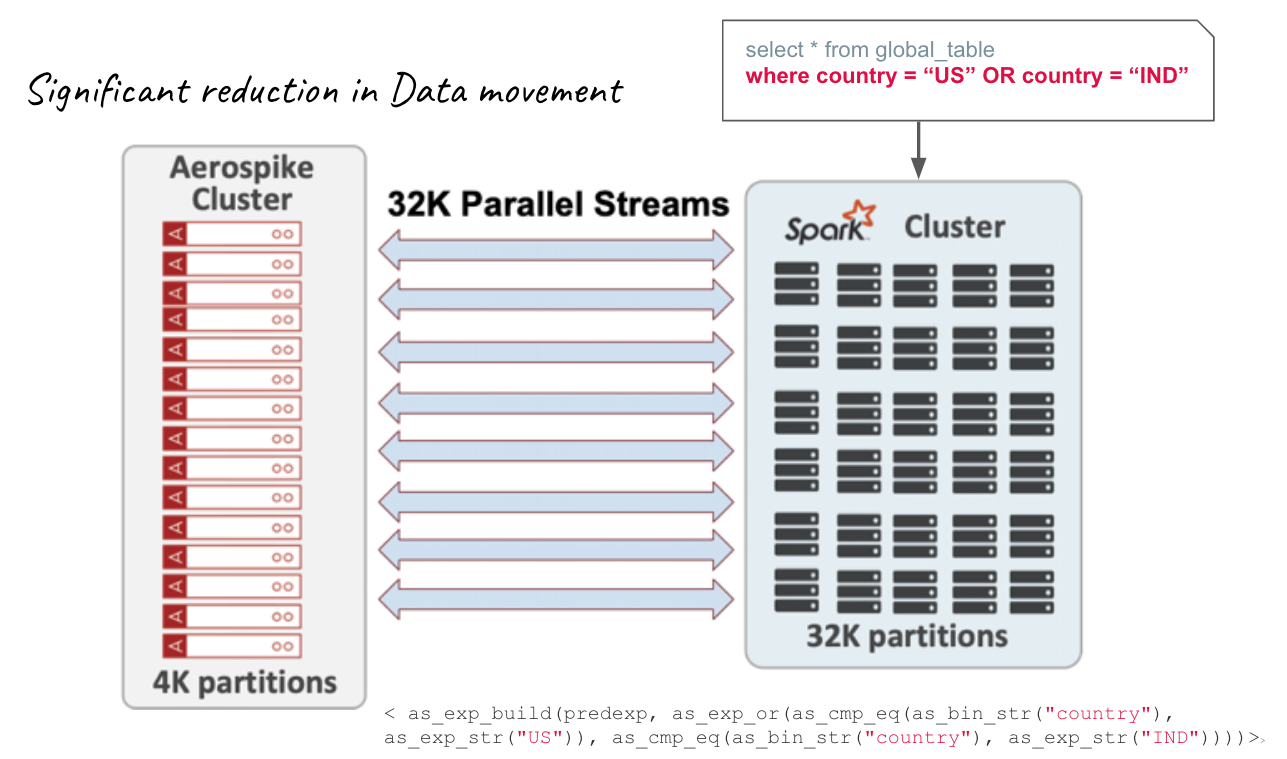
Figure 1: Predicate Pushdown at scale**
Everything looks great so far, so what’s the problem:
The Spark filter class that the Aerospike connector uses allows limited operators (see Figure 2) in a predicate to be pushed down to the database, hence the Spark connector is limited in the number of Aerospike expressions that it can generate and push down to the database.

Figure 2: Spark Filter class supported filters
In the case of the below SQL query, the connector converts “EqualTo” and “Or” operators in Spark to Aerospike eq and Or operators and pushes them down to the DB as shown in Figure 3:

Figure 3: SQL Syntax

Figure 3: WHERE clause is mapped to Aerospike Expressions in the Aerospike Spark Connector
Prior to describing our idea for addressing this limitation, I’d like to walk you through the query plan generation process in Spark from the perspective of loading data from the Aerospike database into a Spark DataFrame. As described in Figure 3, the SQL query in either the SQL format or the DataFrame format is converted into a logical plan. Spark Catalog or the metastore is consulted during this conversion for resolving attributes such as database(s), tables, functions, columns, etc. Spark has its own optimizer called the Catalyst, that performs a set of source-agnostic optimizations on the logical plan like predicate pushdowns, constant folding, etc. In the Physical planning phase, one or more physical plans are formed from the logical plan and only one is selected based on the cost model. The details of how the plan is optimized and a physical plan is selected are beyond the scope of this blog. However, plenty of literature is available on that topic. The final stage of Spark SQL optimization is code generation. It involves generating Java bytecode to run on each machine. Whole-Stage CodeGen is also known as Whole-Stage Java Code Generation, which is a physical query optimization phase. The code for Aerospike read/write calls is generated in this stage via the Aerospike Spark Connector (distributed as a JAR and specified as a dependency in the Spark application) and the Spark Filter class and the selected physical plan is updated subsequently. Finally when the code is executed, data is loaded from the Aerospike database into Spark RDDs.
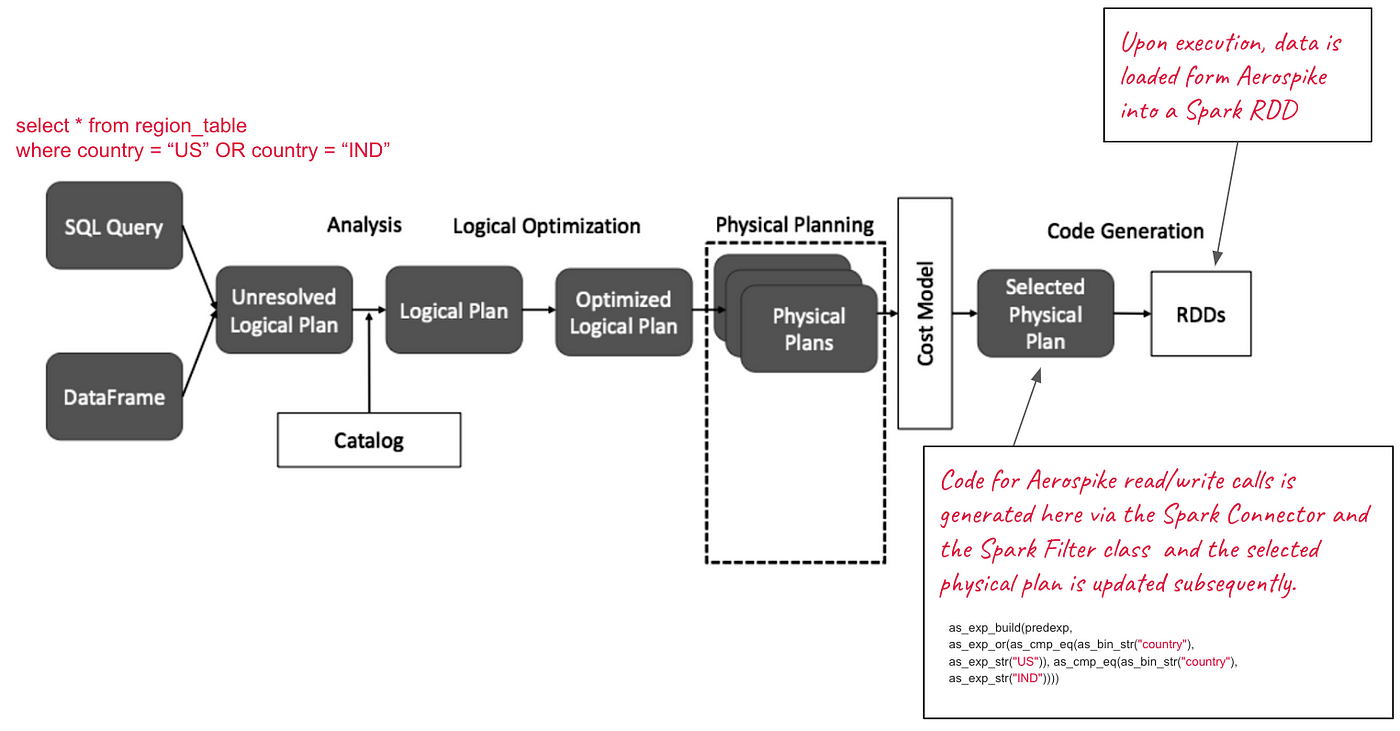
Figure 4: Spark Query planning process with Aerospike Spark Connector
Side-channel approach for pushing down predicates
Our idea does not involve altering the Spark query planning process. It rather uses the existing Spark provided constructs such as “.option()” to insert user provided Aerospike expressions into the query plan in the code generation phase. You can think of it as a side-channel approach for pushing down predicates i.e the right side of the WHERE clause in your SQL statement. This essentially guarantees that the left side of the WHERE clause is not impacted at all. While using the aforementioned side-channel approach, we ask our users not to use the WHERE clause because that would mess up the query planning process. The user is also expected to use the Base64 encoded version of the expressions string, which can be realized using either the Aerospike Java or Python client. Further, this approach is not language constrained and can be used in Java, Scala, and Python as you see fit. Above all, it lets you bring to bear the whole gamut of Aerospike expressions as required by your use case.
You can easily push down an expression to the database using the following single statement in the Spark read API:
.option(“aerospike.pushdown.expressions”, <Base64 encoded expressions string>)Why should you care:
Figure 5 shows a screenshot of a Jupyter notebook with the sample code to fetch every 5th record in the DB. There are about 199 records in the DB, so only 39 records are moved to the Spark cluster as opposed to fetching 199 records from the database and filtering them down to 39 in Spark. The reduction in data movement will allow your queries to run faster. You can view the entire code in our Spark connector documentation.
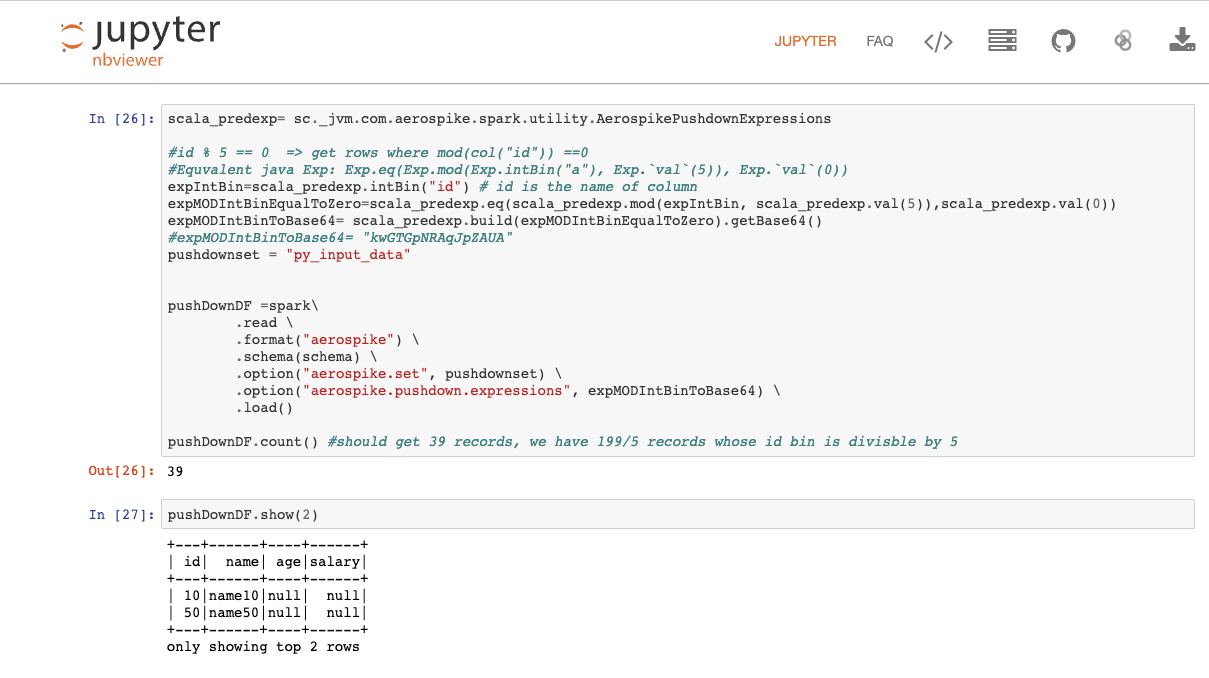
Figure 5: Sample Python code for MOD operator pushdown
Figure 6 depicts a comparative situation, where as shown in the Spark UI, the query without the predicate pushdown yields a batch scan of 80 million records, which is basically the whole dataset. However, in the pushdown scenario, only 80 thousand records are read from the database, which reduces the data movement significantly, thereby accelerating the query. You can imagine the performance gains when you run your Spark query against a billion record table that is stored in Aerospike.
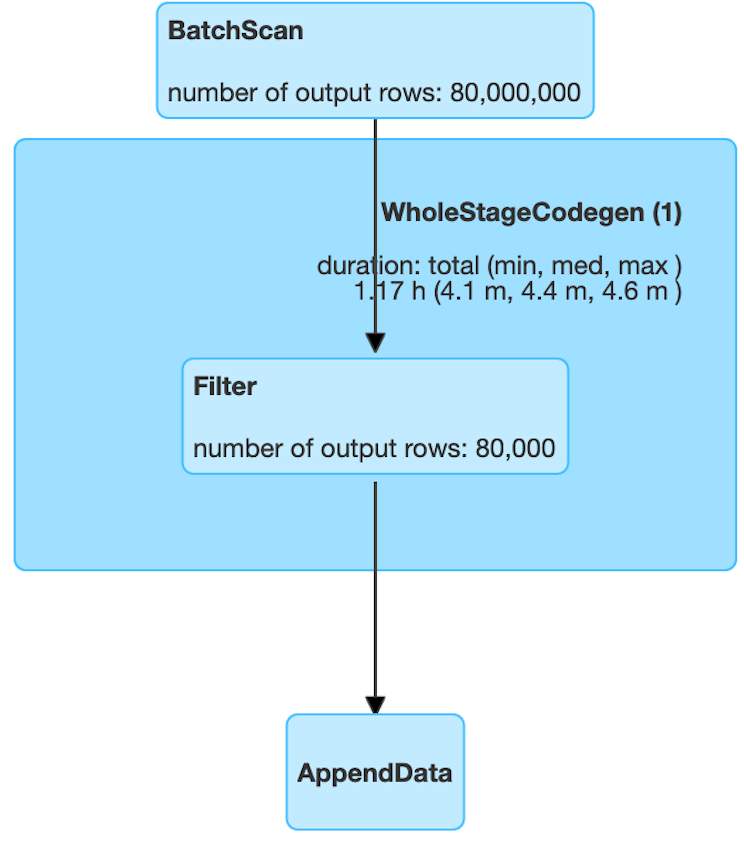
Figure 6: Spark UI view to capture the impact of the pushdown (Before)
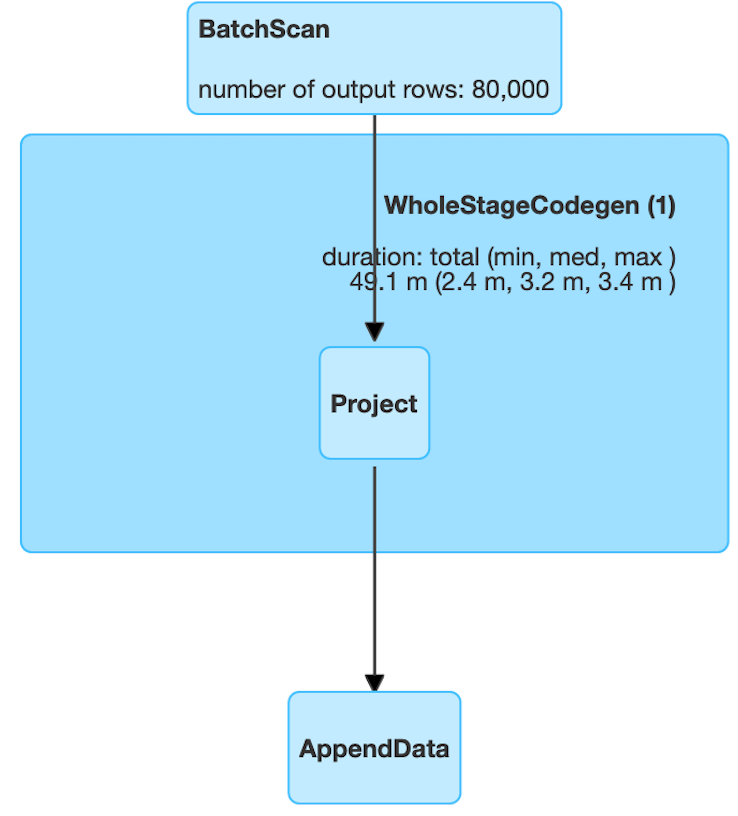
Figure 6: Spark UI view to capture the impact of the pushdown (After)
You can view the entire code in Scala at this location.
What’s next:
In this blog, we have described a novel way to address a limitation in Spark around predicate pushdown. It is not only easy to use but is also non-intrusive to the tried and tested Spark query planning process, not to mention you can bring the full power of Aerospike Expressions to bear. In the future we plan to introduce new features such as querying using secondary index in the Aerospike Spark connector to further boost the performance of your Spark queries. Stay tuned!
If this blog has inspired you to trial this capability, please download the Aerospike connect for Spark, full-featured single-node Aerospike Database Enterprise Edition, Spark Jupyter notebook, and follow our documentation for a seamless trial experience.
I’d like to thank my colleagues Rahul Kumar and Joe Martin for developing this feature.
Aerospike is hiring! If you’re interested in technical challenges within a growing team, take a look at our available jobs.